
这里整理一下关于Http协议的学习笔记。
注:文章中的部分图片来自于网络,侵删
TCP/IP五层模型
大学学过计算机网络课的都知道OSI模型,即计算机网络模型,OSI模型由7层组成,除了OSI模型还有网络协议栈(也称为TCP/IP模型),其表示如下图(图片来自网络)所示:
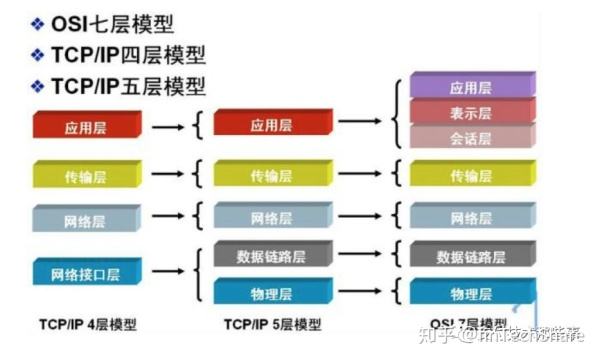
一般我们都使用五层模型的概念,这里就以五层模型来总结一下各个层的功能。
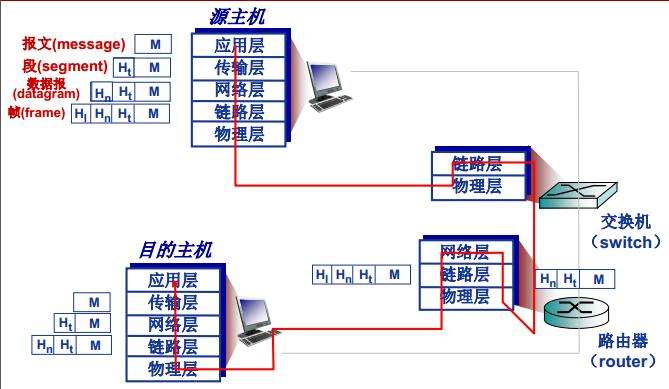
- 应用层:网络应用程序以及对应应用层协议存放的地方,常见如Http,SMTP以及FTP等协议。在两个应用程序进行网络交互的时候,应用层对应生成/获取到的信息分组称之为报文。
- 运输层:负责为端和端提供应用程序进程间的数据传输服务,这一层包含两个传输协议,传输控制协议即TCP和用户数据报协议UDP。TCP提供了可靠的面向连接的服务,使用TCP协议可以确保传递以及流量控制,并且提供拥塞控制。而UDP则提供无连接服务,不可靠,没有流量控制,也没用拥塞控制,单纯传递数据,不保证是否到达对应端。运输层封装的数据称之为报文段,报文段主要是将应用层的报文数据加上运输层生成的信息(如端口号)。
- 网络层:网络层封装的数据称之为数据报,其主要包含运输层传递过来的报文段以及对应IP地址信息。
- 链路层:网络层的数据报封装成合适在物理网络上传输的帧格式并传输,或将从物理网络接收到的帧解封,取出IP数据报交给网络层。因特网的网络层通过一系列路由器在源和目的地之间发送分组。为了将分组从一个节点(主机或路由器)移动到路径上的下一个节点,网络层必须依靠链路层的服务。链路层协议主要有以太网,WiFi以及电缆接入网的DOCSIS协议等。
- 物理层:物理层负责将链路层传递过来的帧转化为一个一个比特进行传输。该层协议仍然与链路层相关,并且进一步与该链路(如单模光纤,双绞铜线等)的实际传输媒体挂钩
五层模型在实际中的通信过程如下所示:
下面一图囊括了大部分的各层协议:
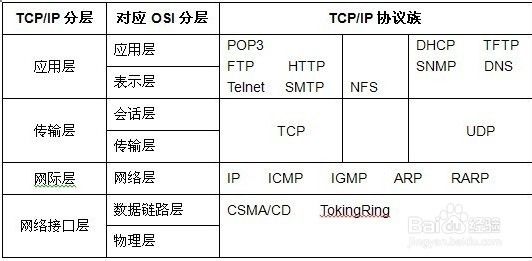
应用层协议介绍
在文章中介绍了套接字的使用,主要用于进行远程进程之间的通信,在计算机网络知识领域,套接作为进程与网络之间沟通的媒介提供了应用层与传输层链接的功能。在应用程序中我们通过将在应用层封装好的报文交付于套接字使得网络进程之间可以进行相互的通信。既然进行通信,就要商量好对应的协议,应用层协议就定义了应用程序进程中如何进行传递报文的。
应用层协议定义了如下的规则:
- 交换报文的类型,例如请求报文以及响应报文。
- 各个报文类型的语法,如报文中各个字段以及字段描述。
- 字段的语义。
- 一个进程何时以及如何发送报文,接受报文的规则。
关于应用层协议可以查看RFC文档来了解对应详细规则。
Http协议
Http(超文本传输协议)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。Http协议使用TCP协议作为传输层的支撑,保证了在传输过程中的可靠性,但是,Http也是一个无状态的协议,即一个请求对应一次响应,服务器只响应客户端的请求,不记录任何状态信息,一秒内发送2次相同的请求,服务器就会响应2次。
当使用TCP的时候,TCP提供了两种连接的方式:非持续性连接以及持续性连接(默认),区别在于每个请求/响应是单独的一个TCP连接发送还是所有的请求都由一个TCP连接发送。
Http报文分为两种:请求报文和响应报文。请求报文的结构如下:
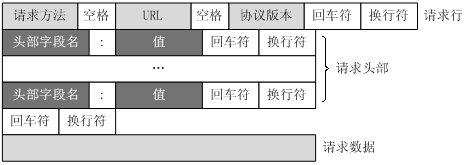
首先查看一个简单的请求报文:
GET /dir/page.html HTTP/1.1Host: www/baidu.comConnection: closeUser-Agent: Mozilla/5.0Accept-language: fr
报文的第一行称之为请求行,后续的称之为首部行(请求头部)。请求行包含三个字段,分别是方法字段,URL字段以及Http版本字段。
关于方法字段,HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。下面是各个方法的意义(图片截图来自菜鸟教程):
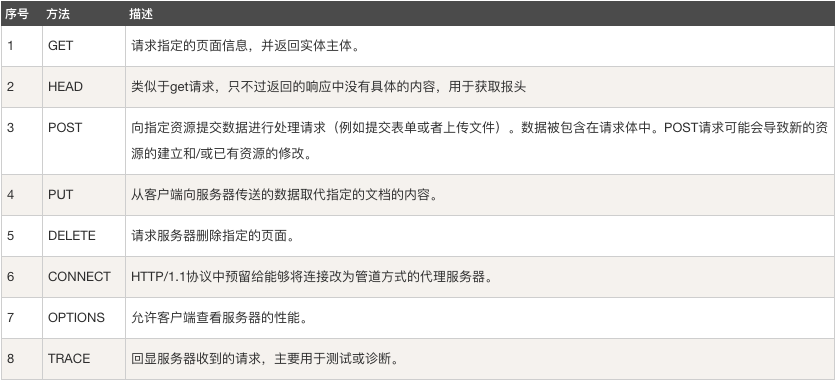
Http中定义了大量的请求头部以及响应头部,详细的可以查看这篇,这里就不详细罗列出来了。从上面的图中还可以看到最后一行为请求数据(请求实体),请求实体在POST中会进行填充数据,如表单数据。
接下来看下响应报文,响应报文的结构与消息报文的结构一致,唯一不同的是叫法,第一行为状态行,然后是响应行(状态行),响应头部,空行和响应正文。看下例子:
HTTP/1.1 200 OKDate: Mon, 27 Jul 2009 12:28:53 GMTServer: ApacheLast-Modified: Wed, 22 Jul 2009 19:15:56 GMTETag: "34aa387-d-1568eb00"Accept-Ranges: bytesContent-Length: 51Content-Type: text/plain
关于Http响应状态码介绍如下:
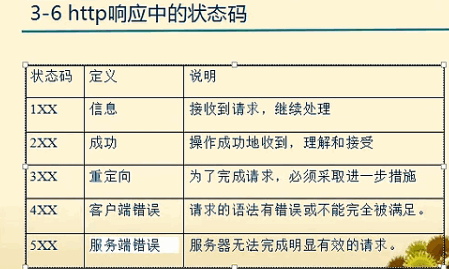
罗列一些例子如下:
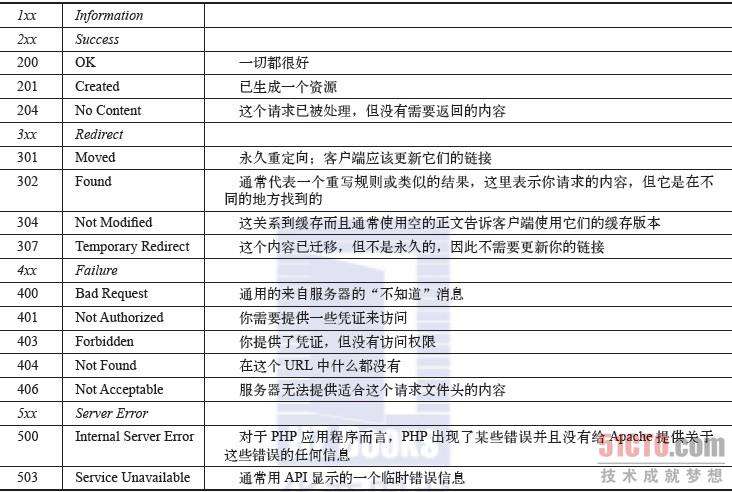
在Http使用中,我觉得需要注意的是两点,一个cookie的使用,另一个是Http的缓存机制。下面对两方面的知识做个整理。
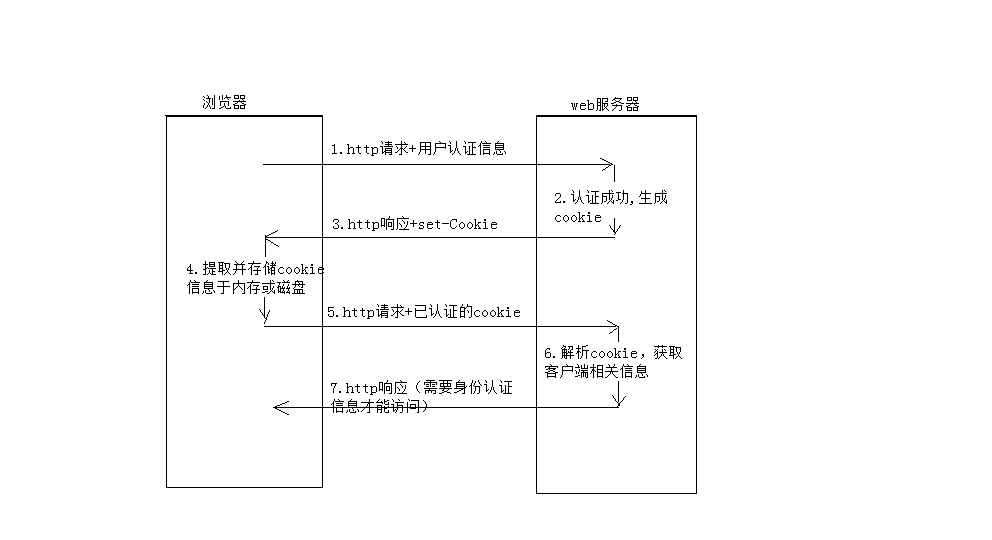
首先是cookie,上述也介绍了Http是一个无状态的,因此也简化了服务器的设计。然而从用户的角度而言,用户更倾向于保存在某个网站上保存一定的信息,如用户信息(chrome上会经常看到提示我们是否保存用户信息),这时候cookie就应运而生了。HTTP Cookie(也叫Web Cookie或浏览器Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
一次完整的cookie使用记录如下,更详细的可以查阅这篇:
接下来就是Http缓存操作,首先自主思考一下如果我们需要自己实现该怎么做呢?
- 首先考虑一种情况,服务器的数据永远是不变的(某张具体的jpg),那么我们就可以在服务器返回字段的时候标明这个数据不会变,客户端在第二次请求的时候发现有缓存,直接使用就可以了。同样的弱可变性也能这么实现。比如我一张图片一个月后过期,那么服务器告诉客户端一个月后过期就可以了。(强制缓存)
- 其次可能存在另一种情况,服务器的数据是可变的,这时候怎么办呢?可以这么做,假设我们在获取一个文件,服务器返回文件的时候把文件的md5告诉我们,客户端把值存下来,在客户端第二次请求的时候,我们把md5传过去,服务器把md5跟最新的文件的md5做比对,如果相同,返回一个相同的字段给客户端,客户端直接使用本地缓存即可;如果不相同,那么服务器再把文件以及md5返回给客户端。(对比缓存)
既然我们能想到,开发Http协议的人可能比我们更厉害咯,下面总结一下这两种缓存方式对应Http的实现。
首先是Expires(对应第一种缓存情况)以及Pragma,Expires,Pragma都是Http1.0的产物,Pragma主要控制是否允许客户端缓存,如果服务器返回了:
Pragma: no-cache
那么就是告诉客户端禁止缓存,每次数据都从服务器去拿。Expires字段来自响应实体,服务器在返回数据时候可以加上当前字段来设置缓存时间,如底下返回数据:
Expires: Wed, 21 Oct 2015 07:28:00 GMT
Expires返回一个GMT标准时间,客户端获取之后存入数据库,在缓存时间内使用缓存,否则再次请求服务器。如果Expires,Pragma一起返回,Pragma的优先级高于Expires,即客户端不允许缓存。
响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,其定义的是资源“失效时刻”,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了。
接着介绍一下Cache-Control,Cache-Control在Http1.1中实现。Cache-Control的请求实体可选参数如下:
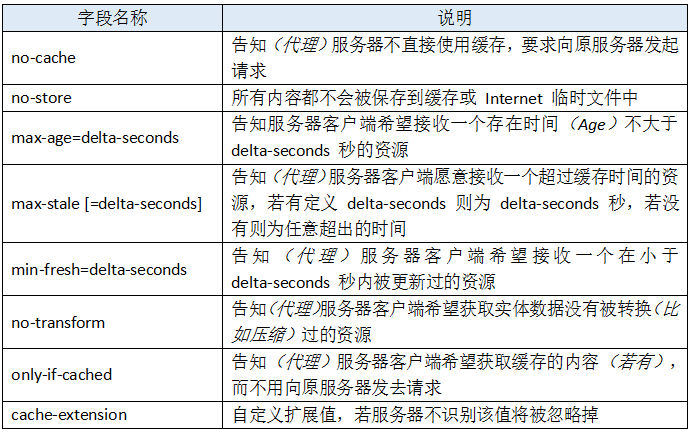
响应实体可选参数如下:
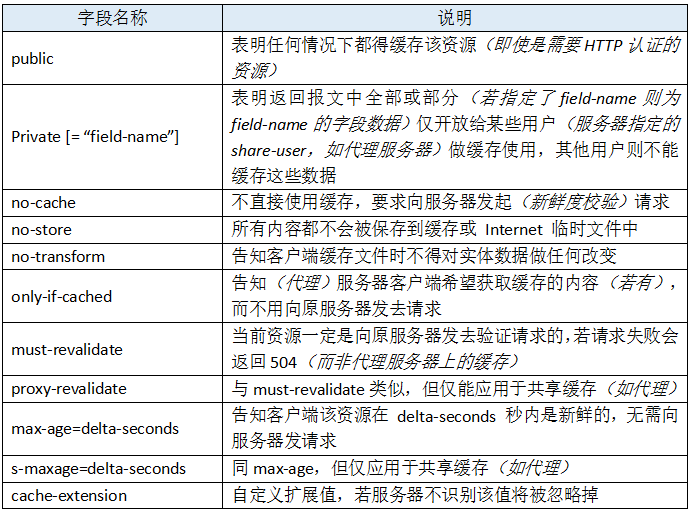
Cache-Control配合其他关键字能实现我们上面说的任何一种缓存方式。这边我们说的对应于响应实体Cache-Control,因为相对于客户端开发而言,客户端对于服务端的缓存策略控制相对叫弱。Cache-Control中通过max-age也实现了Expires的功能,不同的是,max-age返回的是时间值,而不是明确的时间,如:
Cache-Control: max-age=36000
由于返回的是时间值,就可以趋避客户端时间与服务器时间相差较大的情况,从而解决了Expires的局限性。与Pragma对应的是no-store参数。
对比缓存实现主要有两种途径:Last-Modified/If-Modified-Since以及Etag/If-None-Match方式。
使用Last-Modified/If-Modified-Since方式的流程图如下:
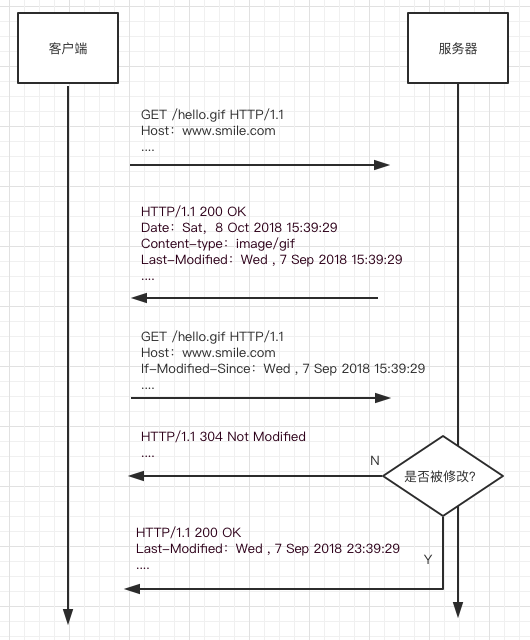
Last-Modified主要回传的是对应文件服务器端最后修改的时间,客户端在第二次调用时将Last-Modified获得到的value存放在If-Modified-Since中重新传给服务端,服务端做数据比对,并返回对应的状态码给客户端,如果返回304,代表服务器数据未更新,直接使用客户端维护的缓存即可;更新了,返回200并带上数据发送给客户端。
通过Last-Modified也有一定的局限,如果一个文件更新了但是其内容本质上不变,那么服务器也会认为客户端需要进行更新数据,从而返回服务器认为更新后的,但是实际上没有更新的数据,这样造成了客户端重新获得一个一模一样的文件。
由于Last-Modified的局限性,因此引入了Etag参数,Etag代表了文件的唯一标识码(如md5),Etag和If-None-Match一同使用,使用的流程如下图:
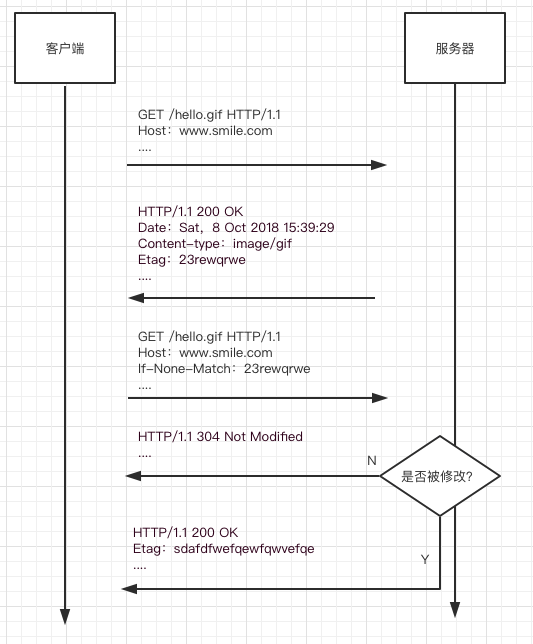
流程跟Last-Modified/If-Modified-Since一致。
总结一下相关关键字调用的优先级:
Pragma -> Cache-Control (max-age>Etag>Last-Modified)-> Expires
放上一张缓存流程图:

这里总结一下一题面试题吧,叙述一下在浏览器中输入
- 判断本地是否有缓存,如果是强制缓存,则直接返回缓存数据,请求执行结束,如果是对比缓存,则向服务端在请求体中添加参数If-None-Match/If-Modified-Since。
- DNS解析域名获取目标IP地址。
- 进行TCP三次握手过程,确认连接。
- 服务端发送数据,进行四次握手,一次请求结束。
参考资料
<<计算机网络-自顶向下方法>>